웹 개발자의 KPI(Key Performance Indicator)는 개인의 업무 성과와 팀 목표를 측정하는 데 도움이 됩니다. 아래는 일반적인 주니어 웹 개발자를 위한 KPI 항목입니다:
코드 품질 및 생산성 • 코드 리뷰 피드백 반영률: 코드 리뷰에서 지적된 사항을 얼마나 잘 반영했는지. • 주간/월간 코드 기여도: 작성한 코드의 라인 수보다는 기능의 완성도와 기여도를 평가. • 버그 발생률: 작성한 코드에서 발견된 버그의 수. • 테스트 커버리지 향상: 테스트 작성 여부와 코드 커버리지 증가율.
프로젝트 완료 및 기여 • 기한 준수율: 맡은 작업이나 프로젝트를 제때 완료한 비율. • 작업 완료 건수: 주어진 업무(예: Jira 티켓, Git 이슈) 처리 수량. • 기능 구현의 정확성: 요구사항을 충족하며 기능을 개발한 정도.
학습 및 성장 • 새로운 기술 습득: 업무와 관련된 새로운 기술, 프레임워크, 툴을 학습한 정도. • 교육 참여: 팀 내 세미나, 워크숍 또는 외부 교육 프로그램 참여율. • 지식 공유: 팀원들에게 학습한 내용을 공유하거나, 문서화한 빈도.
협업 및 커뮤니케이션 • 커뮤니케이션 명확성: 팀원 및 이해관계자와 명확히 소통하는 능력. • 팀워크 기여도: 코드 리뷰 참여, 동료와의 협업 빈도 및 품질. • 이슈 해결 참여: 문제를 발견하고 해결하는 데 기여한 빈도.
운영 및 유지보수 • 배포 안정성: 개발한 코드가 운영 환경에서 문제 없이 배포된 비율. • 긴급 문제 해결 기여: 운영 환경에서 발생한 문제를 얼마나 효과적으로 지원했는지. • 기존 코드 개선: 리팩토링, 성능 최적화 등 기존 코드에 대한 기여.
사용자 중심 개발 • 사용자 피드백 반영률: 사용자 요구사항을 코드에 잘 반영했는지. • UX/UI 향상 기여도: 사용자 경험과 인터페이스 개선 기여.
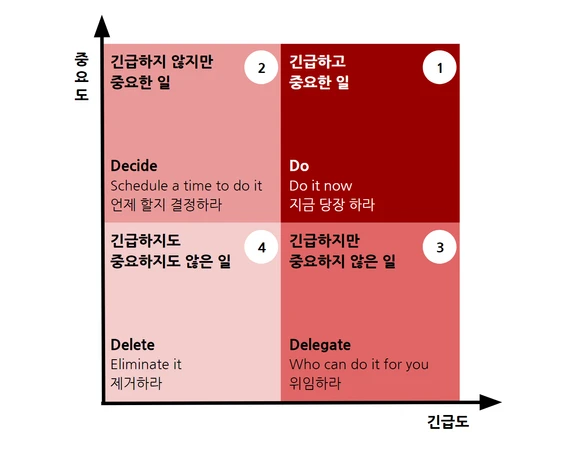
업무의 우선순위를 먼저 해야 할 일, 계획해야 할 일, 위임할 일, 하지 않아도 될 일 4단계로 분류
업무 우선순위
자신의 업무를 모두 나열
각 업무의 긴급성과 중요도 판단
업무를 4개의 카테고리로 분류
긴급하고 중요한 일 - 먼저 해야할 일
긴급하지 않지만 중요한 일 - 계획해야 할 일
긴급하지 않지만, 중요하지 않은 일 - 위임할 일
긴급하지도, 중요하지 않은 일 - 하지 않아도 될 일
아이젠하워 매트릭스에 따라 우선순위 확인하고, 일정 계획
아이젠하워 매트릭스
아이젠하워 매트릭스
중요하고 급한 일 - 먼저 한다 명확한 결과가 따르며 장기 목표에도 영향을 주는 업무로서, 가장 먼저 해야 하는 업무입니다. 이 카테고리 안의 업무들은 미루지 않고 바로 처리하는 것이 좋습니다.
중요하지만 급하지 않은 일 - 계획한다 장기 목표에 영향을 미치지만 당장 처리하지 않아도 되는 일입니다. 긴급하지 않기 때문에 신중하게 준비하고 계획하여 완성도를 높일 수 있습니다. 중요하고 급한 일을 해결한 뒤 이 카테고리 안의 업무를 처리합니다. 이 업무들을 마냥 미뤄두지는 않도록 주의해야 하며, 집중력을 발휘하여 수행할 수 있도록 합니다.
중요하지 않지만 급한 일 - 위임한다 바로 처리되어야 하지만 장기 목표에는 영향을 미치지 않는 업무입니다. 이러한 업무는 에너지 소모가 많지만 특별한 기술은 요하지 않는 잔업인 경우가 많습니다. 꼭 본인이 직접 하지 않아도 되는 일이기 때문에, 다른 사람에게 위임하거나 대체 시스템을 마련하도록 합니다.
중요하지도 급하지도 않은 일 - 하지 않는다 목표를 달성하는 데 방해가 되는 일입니다. 업무 목록에서 삭제하도록 합니다.
Caching은 H/W, S/W 전반에 걸쳐 사용되는 기술이다.
DB - application 뿐 아니라 클라이언트나 CDN에서도 캐싱을 사용한다.
이 글에서는 DB - Web Application의 캐싱만 다룬다.
서비스 응답시간에 큰 영향을 미치는 부분은 주로 네트워크 통신과 DB I/O이다. 캐싱을 통하면 DB I/O로 인해 발생하는 오버헤드를 줄일 수 있다.
서론
Caching?
캐시는 빠른 응답과 비용 절약을 위해 사용하는 임시 데이터다.
클라이언트의 요청으로 특정 데이터가 필요한 경우 서버는 DB에 질의한 뒤 결과를 반환한다.
만약 요청하는 데이터의 캐시가 존재한다면 DB에 질의하지 않고 캐시로부터 데이터가 반환된다.
캐기사 없다면? DB에 질의가 수행되어 반횐되고 그 결과를 캐싱한다.
캐시의 관리
캐시는 임시 데이터다. 따라서 캐시를 저장할 때 캐시가 만료되는 시간 (expire time || TTL; Time To Live)를 명시한다. 캐시는 해당 시간 내에서만 유효하고 만료 시간이 경과하면 사용할 수 없다.
캐시에 만료되는 시간을 두는 이유는 캐시가 실시간 데이터가 아니기 때문이다. 만약 원본 데이터가 바뀐다면 캐시된 내용도 바뀌어야 한다.
캐시를 사용하는 이유
캐시를 사용하면 DB에서 데이터를 읽을 때 발생하는 I/O 오버헤드를 줄일 수 있다. 캐시는 보통 Redis와 같은 In-Memory DB를 사용한다. In-Memory DB는 메모리를 사용하기 때문에 일반적인 RDBMS보다 데이터를 읽는 속도가 빠르다. 따라서 캐시는 DB에서 데이터를 읽는 것 보다 월등히 속도가 빠르다.
모든 데이터를 캐싱하는 건?
In-Memory DB를 사용하면 요청을 빠르게 처리할 수 있지만, 메모리 특성상 데이터 소실의 위험이 있다. 또한 메모리 사용은 비용이 발생하기 때문에 방대한 양의 데이터를 모두 메모리에 적재하는 것은 큰 비용이 든다.
캐시 설계 전략이 필요한 이유
따라서 데이터의 특성에 따라 DB와 캐시를 적절히 사용하는 것이 매우 중요하다. 캐싱 전략을 올바르게 수립하면 적은 비용으로 큰 퍼포먼스 향상을 기대할 수 있다.
What to Cache
어떤 데이터를 캐싱하는 것이 좋을지 생각해 보아야 한다. 캐싱하기 좋은 데이터의 특성은 다음과 같다.
자주 바뀌지 않는 데이터
자주 사용되는 데이터
자주 같은 결과를 반환하는 데이터
오래 걸리는 연산의 결과
자주 바뀌지 않는 데이터
자주 바뀌지 않는 데이터의 경우, 한 번 캐시로 저장하면 메모리에서 읽어 빠르게 사용가능하다. 원본 데이터가 바뀌면 캐시도 바뀌어야 한다. 자주 바뀌지 않는 데이터의 캐시는 오랫동안 사용이 가능하기 때문에 캐싱하는 것이 효율적이다.
자주 사용되는 데이터
자주 사용되는 데이터는 캐싱하기 좋다. 한 번 캐싱해 놓으면 캐시를 사용하여 다수의 요청을 효율적으로 처리할 수 있다. 다만, 자주 사용될 지라도 매번 결과 값이 다르면 오히려 캐싱하지 않는 것이 낫다. 만약 일정시간 동안 데이터가 변하지 않는 것이 보장되면 해당 시간만큼의 TTL로 짧은 캐시를 생성하면 된다. 예를 들어 검색처럼 새로 요청하더라도 일정 시간 동안 같은 결과가 반환되는 경우에 해당한다.
자주 같은 결과를 반환하는 데이터
자주 같은 결과를 반환하는 데이터의 경우도 캐싱을 적용하기 좋다. 예를 들어 특정 arguments의 조합에 따라 결과가 일정한 경우 해당된다. 이런 경우는 각 arguments의 조합을 key로 연산 결과를 캐싱하면 된다.
오래 걸리는 연산의 결과
무거운 연산이 반복적으로 계산되어야 한다면 연산의 특성에 맞게 결과를 캐시하는 것이 효율적이다. 또는 사전에 별도의 프로세스에서 작업을 수행하여 결과를 미리 캐싱해 놓을 수 있다.
이 밖에도 일반적인 쿼리나 연산보다 캐싱할 때의 비용이 더 적다면 캐싱을 사용할 수 있다. 로그 분석이나 프로파일링을 통해 캐시를 적용할 함수나 API를 찾을 수 있다. 그러나 모든 사항을 고려하여 캐싱을 적용할지, TTL은 얼마나 적용할지 등은 개발자의 선택이 중요하다.
캐싱 전략 패턴의 종류
캐시를 이용하게 되면 닥쳐오는 문제점이 바로 데이터 정합성의 문제이다. 같은 종류의 데이터라도 두 저장소에 저장된 값이 서로 다른 현상이 일어날 수 밖에 없는 것이다. 따라서 적절한 캐시 읽기 전략(Read Cache Strategy)과 캐시 쓰기 전략(Write Cache Strategy)를 통해, 캐시와 DB간의 데이터 불일치 문제를 극복하면서도 빠른 성능을 잃지 않게 하기위해 연구를 할 필요가 있다.
캐시 읽기 전략 (Read Cache Strategy)
Look Aside Pattern
Cache Aside 패턴이라고도 불림.
데이터를 찾을 때 우선 캐시에 저장된 데이터가 있는지 우선 확인, 캐시에 데이터가 없으면 DB에서 조회함.
반복적인 읽기가 많은 호출에 적합.
캐시와 DB가 분리되어 가용되기 때문에 원하는 데이터만 별도로 구성하여 캐시에 저장.
캐시와 DB가 분리되기 때문에 캐시 장애 대비 구성이 되어 있음. 만일 Cache Store가 다운되더라도 DB에서 데이터를 가져올 수 있어 서비스 자체는 문제가 없음.
대신 Cache Store에 붙어있던 connection이 많았다면, Cache Store가 다운된 순간 DB로 몰려 부하발생 가능.
일반적으로 사용되는 기본적인 캐시 전략. 이 방식은 캐시에 장애가 발생하더라도 DB에 질의를 실행함으로 캐시 장애로 인한 서비스 문제는 대비할 수 있지만, Cache Store와 DB간 정합성 유지 문제가 발생할 수 있음. 반복적으로 동일 쿼리를 수행하는 서비스에 적합, 단건 호출 빈도가 높은 서비스에는 비적합. 이런 경우 DB에서 캐시로 데이터를 미리 넣어주는 작업을 하기도 하는데 이를 Cache Warming이라고 함.
Read Through 패턴
캐시에서만 데이터를 읽어오는 전략 (inline cache)
Look Aside와 비슷하지만 데이터 동기화를 라이브러리 또는 캐시 제공자에게 위임하는 방식이라는 차이가 있음.
따라서 데이터를 조회하는데 전체적으로 속도가 느림.
또한 데이터 조회를 전적으로 캐시에만 의지하므로 Cache Store가 다운될 경우 서비스 이용에 차질이 생길수 있음.
캐시와 DB간의 데이터 동기화가 항상 이루어져 데이터 정합성 문제에서 벗어날 수 있음.
읽기가 많은 호출에 적합
Cache Aside 방식과 비슷하지만, Cache Store에 저장하는 주체가 Server인가 혹은 Data Store 자체인가의 차이가 있음. 직접적인 DB 접근을 최소화 하고, Read에 대한 소모되는 자원을 최소화할 수 있음. 하지만 캐시에 문제가 발생하는 경우 바로 서비스 중단이 되기 때문에 Cache Store의 Replication 또는 Cluster구성하여 가용성을 높여야 함.
캐시 쓰기 전략 (Write Cache Strategy)
Write Back 패턴
Write Behinde 패턴이라고도 불림.
캐시와 DB 동기화를 비동기하기 때문에 동기화 과정이 생략.
데이터를 저장할 때 DB에 바로 질의하지 않고, 캐시에 모아서 일정 주기 배치 작업을 통해 DB에 반영.
캐시에 모아놨다 DB에 쓰기 때문에 쓰기 커넥션 회수 비용과 부하를 줄일 수 있음.
Write가 빈번하면 서 Read를 하는데 많은 양의 리소스가 소모되는 서비스에 적합.
데이터 정합성 확보.
자주 사용되지 않는 불필요할 리소스 저장.
캐시에서 오류발생시 데이터 영구소실의 가능성.
데이터를 저장할 때 DB가 아닌 캐시에 먼저 저장하여 모아놓았다가 특정 시점마다 DB로 쓰는 방식으로 일종의 Queue 역할을 겸하게 됨. 캐시에 데이터를 모았다 한 번에 DB에 저장하기 때문에 DB 쓰기 횟수 비용과 부하를 줄일 수 있지만, 데이터를 옮기기 전에 캐시 장애가 발생하면 데이터 유실이 발생할 수 있다는 단점이 존재. 반대로 DB에 장애가 발생하더라고 지속적인 서비스 제공을 보장하기도 함. Replication이나 Cluster 구조를 적용하면 Cache Store 서비스의 가용성을 높일 수 있고, Read Through와 결함하변 가장 최근에 업데이트 된 데이터를 항상 캐시에서 사용할 수 있음.
Write Through 패턴
DB와 Cache에 동시에 데이터를 저장하는 전략.
데이터를 저장할 때 먼저 캐시에 저장한 다음 DB에 저장.
Read Trough와 마찬가지로 DB 동기화 작업을 캐시에 위임.
DB와 캐시가 항상 동기화 되어 있어, 캐시의 데이터는 항상 최신 상태로 유지.
캐시와 백업 저장소에 업데이트를 같이 하여 데이터 일관성 유지.
데이터 유실이 발생하면 안 되는 상황에 적합.
자주 사용되지 않는 불필요한 리소스 저장.
매 요청마다 두번의 Write 가 발생함으로 빈번한 생성, 수정이 발생하는 서비스에서는 성능 이슈 발생.
기억장치 속도가 느릴 경우, 데이터를 기록할 때 CPU가 대기하는 시간이 필요하기 때문에 성능 감소.
Cache Store와 DB에 동시에 반영하는 방식. 항상 동기화 되어 있고 항상 최신정보를 가지고 있다는 장접이 있음. 저장할 때마다 2개 과정을 거치기 때문에 상대적으로 느림.
Write Around 패턴
모든 데이터는 DB에 저장
Cache Miss가 발생하는 경우에만 DB와 캐시에 데이터 저장
DB와 Cache Store의 데이터가 다를 수 있음.
Cache Miss가 발생하기 전에 DB에 저장된 데이터가 수정되었을 때, 사용자가 조회하는 Cache Store와 DB 간의 데이터 불일치 발생.
Cache 읽기 + 쓰기 전략 조합
Look Aside + Write Around
Read Through + Write Around
Read Through + Write Through
캐시 저장시 참고
Cache Hit Ratio : 캐시 사용의 정중도. 적중율이 높을 수록 CPU와 주기억장치 속도 차이로 인한 병목현상을 최소화할 수 있다. 자주 사용되면서 자주 변경되지 않는 데이터를 캐시에 저장할 경우 높은 성능 향상을 이뤄낼 수 있다.
지역성 (Locality) : Cache Hit Ratio는 캐시의 Locality, 즉 지역성에 의해 높아진다. 지역성이란 데이터 접근이 시간적 혹은 공간적으로 가깝게 일어나는 것을 의미함.
시간적 지역성 : 최근에 엑세스 된 프로그램이나 데이터가 가까운 미래에 다시 엑세스 될 가능성이 높은을 의미.
공간적 지역성 : 기억장치 내에 인접하여 저장된 데이터들이 연속적으로 엑세스 될 가능성이 높음을 의미.
순차적 지역성 : 분기가 발생하지 않는 이상 명령어들이 기억장치에 저장된 수서대로 인출되어 실행됨을 의미
일반적으로 캐시는 메모리에 저장되는 형태를 선호한다.
메모리 저장소(Cache Store)는 대표적으로 Redis와 MemCached가 있으며, 메모리를 1차 저장소로 사용하기 때문에 디스크와 달리 제약적인 저장 공간을 사용한다.
자주 사용되는 데이터를 어떻게 뽑아 캐시에 저장하고 자주 사용되지 않는 데이터는 어떻게 제거해 갈것이냐를 지속적으로 고민해야 할 필요성이 있다.
캐시는 자주 사용되며 자주 변경되지 않는 데이터를 기준으로 하는 것이 좋다.
캐시는 휘발성을 기본으로 하기 때문에 어느 정도 데이터 수집과 저장 주기를 가지도록 설계해야 한다.
유실 또는 정합성이 일부 깨질 수 있다는 점을 항상 고려해야 한다.
레파토 법칙 (8:2 법칙) 전체 결과의 80%가 전체 원인의 20%에서 일어나는 현상을 가리킨다. 80%의 활동을 20%의 유저가 하기 때문에 20%의 데이터만 캐시해도 서비스 대부분의 데이터를 커버할 수 있다는 의미다.
캐시 제거시 참고
캐시는 기본적으로 영구 저장소에 저장된 데이터의 복사본으로 동작하는 경우가 많다.
데이터 동기화 작업이 반드시 필요하다는 의미로 개발시 고려해야 한다.
캐시 만료 정책이 제대로 구현되지 않은 경우 클라이언트는 데이터가 변경되었음에도 오래된 정보가 캐싱되어 오래된 정보를 사용할 수 있다는 문제점이 있다.
따라서 캐시 구성시 기본 만료정책을 설정해야 한다.
만료 주기가 너무 짧으면 데이터는 너무 짤리 제거되고 캐시의 이점이 줄어든다.
만료 주기가 너무 길면 데이터 변경의 가능성과 메모리 부족현상, 자주 사용해야 하는 데이터가 제거되는 등의 역효과를 나타낼 수 있다.
Cache Stampede 현상
TTL 값이 너무 작게 설정될 경우 발생할 수 있는 현상이다.
Cache Miss로 DB에 데이터를 요청한 뒤, 다시 Cache Store에 저장하는 과정을 거칠 경우 모든 application에서 DB에서 값을 찾는 duplicate read가 발생한다.
읽어온 값을 각각 Cache Store에 저장하는 duplicate write도 발생하여 처리량도 다 같이 느려질 뿐 아니라 불필요한 작업이 굉장히 늘어나 폭주장애로 이어질 가능성이 있다.
캐시 공유시 참고
캐시는 application의 여러 인스턴스에서 공유하도록 설계한다.
각 application의 인스턴스가 캐시에서 데이터를 읽고 수정할 수 있다.
캐시 업데이트 방식
캐시 데이터의 변경 직전에 데이터가 검색된 후 변경되지 않았는지 확인해야 한다. 변경되지 않았다면 업데이트하고 변경되었다면 업데이트 여부를 어플리케이션 레벨에서 결정할 수 있어야 한다.
캐시 데이터를 업데이트 하기 전에 Lock을 잡는 방식. lock을 사용할 경우 조회성 업무를 처리하는 서비스에 Lock으로 인해 대기현상이 발생할 수 있다.
캐시 가용성 참고
캐시를 구성하는 목적은 빠른 성능 확보와 데이터 전달에 있으며 데이터의 영속성 보장하기 위함은 아니다. 데이터의 영속성은 기존 RDBMS에 위임하고, 캐시는 데이터 읽기에 집중하는 것이 성능확보의 지침사항이다. 또한 Cache Store가 장애로 인해 다운 되었을 경우나 서비스가 불가능 할 경우에도 지속적인 서비스가 가능해야 한다. 이는 데이터가 결국 RDBMS에 동일하게 저장되고 유지된다는 점을 뒷바침 한다.
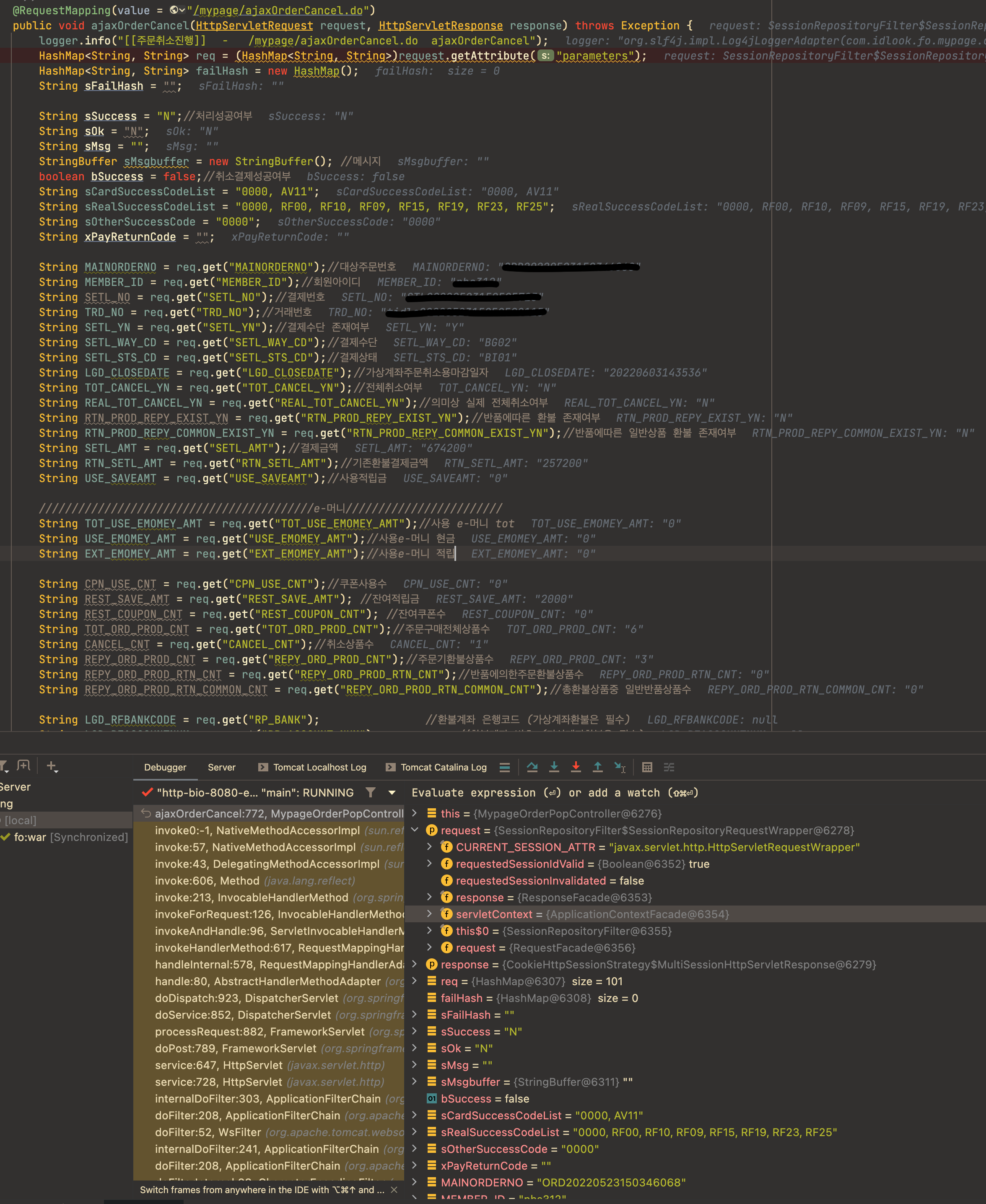
디버그 모드로 애플리케이션을 구동시키면 아래 스크린샷과 같이 변수, 객체 등의 값을 알 수 있다. log를 찍거나 system print 등을 사용하지 앖아도 실시간으로 값을 알 수 있고 브레이크 포인트를 사용해서 트래킹 하는데 수월하니 앞으로는 IDE의 디버그 모드를 적극 활용하자. intellij 나 eclipse 모두 지원한다.
IntelliJ의 디버그 모드
2. Comment 제거
아래 기준을 참고해서 과감하게 기존 코멘트를 제거한다.
위 디버그 모드 활용과 더불어 단순 값 확인용 코멘트는 제거한다.
의미없는 ‘//////////////’ 와 같은 구분선 종류의 코멘트는 제거한다.
Github을 통해 트래킹, 복원이 쉽기 때문에 불필요한 주석은 과감하게 제거한다.
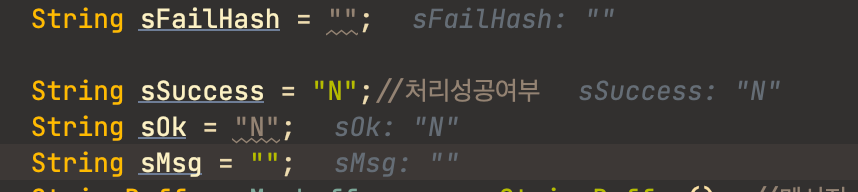
3. 선언, 초기화, 디폴트에 신경쓰자
코드 품질은 디테일에서 나온다. 그리고 디테일은 기본기 없이 챙기기 힘들다. 아래 스크린샷을 보자.
선언부 이후에 로직 중에 항상 해당 변수에 값을 할당한다면 굳이 선언하면서 초기화 할 필요가 없다.
의미없는 값으로 대충 초기화 하는 습관은 멀리하자. 초기화 하는 값은 일반적으로 디폴트 값이어야 하고 이 디폴트 값이 뭔지 정확히 알고서 초기화 해야한다.
4. 가독성을 높이자
// Before
// 결제상점아이디에 따른 분기
if (TRD_NO.indexOf(oldIdPart) >= 0) {
sMallID = oldMid;
}
// After
if (TRD_NO.contains(oldIdPart)) {
sMallID = oldMid;
}
위 코드는 파라미터로 넘긴 string의 존재 여부를 검사한 뒤 그에 따른 처리를 하기위한 것으로 보인다. 그래서 자바의 String에 있는indexOf() 메소드를 사용해 >= 0 조건으로 판별한다. 이 코드는 기능상 아무 이상 없이 작성자의 의도대로 잘 작동한다.
앞서 이야기한 것처럼 이런 코드에서 보이는 디테일을 잡으면 가독성과 품질이 상승한다.
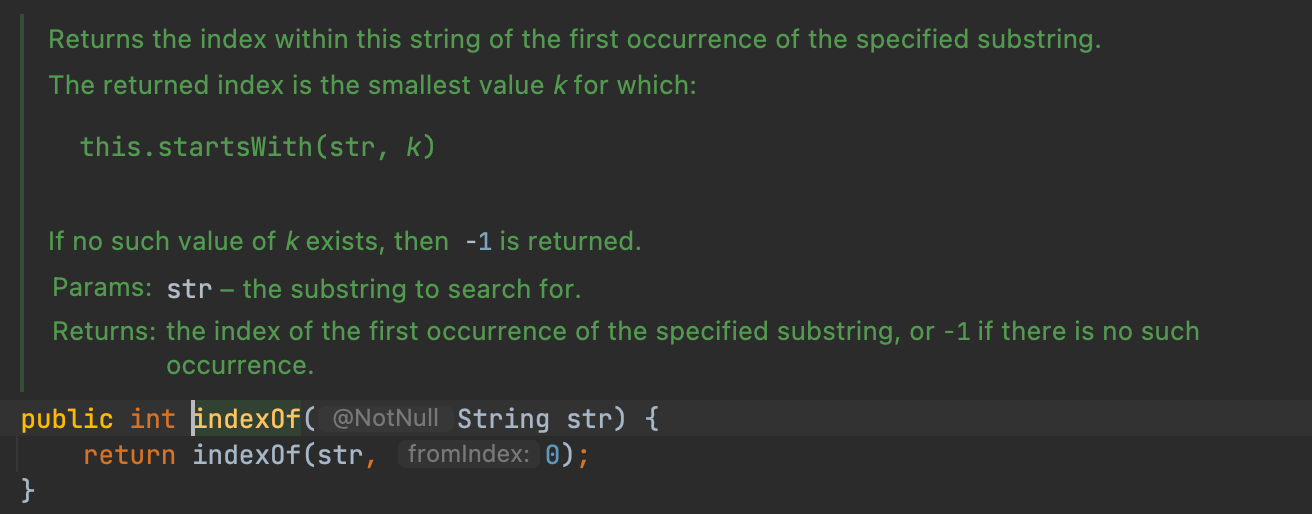
indexOf 와 contains
자바에는 각 객체를 위한 유틸 메소드들이 많다. 그 중 contains라는 메소드로 indexOf를 대체할 수 있다. contains의 내용은 아래 스크린샷처럼 indexOf를 래핑한 메소드다. 따라서 성능이나 기능에선 차이가 없다고 봐도 된다.
JDK 1.5에 생긴 containsindexOf
그럼 왜 indexOf를 contains로 대체하려고 하는거고 언제 써야 할까?
indexOf와 contains는 용도가 다르다.
indexOf는 스트링이 시작되는 index를 int값으로 반환하고 contains는 스트링의 포함 여부를 판단해 boolean으로 반환한다. 따라서 특정 비즈니스 로직 혹은 알고리즘을 구현하기 위한 경우가 아니면 일반적인 경우에 contains의 목적으로 더 많이 쓰게 된다.
Readability
물론 indexOf를 보고 >= 0 조건을 보면 뭘 하려는지 알 수 있다. 하지만 contains라는 단어가 그 모든걸 포함하기 때문에 훨씬 더 직관적이다. contains쓰면 indexOf라는 메소드는 잘 썼는지, 뒤에 >=0 인지 > 0 인지 > -1 인지 잘못쓰진 않았는지 이런 생각 할 필요도 없다. 가독성을 정의할 때 그저 문자가 잘 읽히는 정도를 넘어서 (특히 메소드는) 이름에 맞는 목적과 기능을 신뢰할 수 있어서 불필요한 생각도 줄여주는 수준까지 갈 수 있도록 신경써야 한다.
5. Naming - 변수명은 중요하다
현재 레거시 코드의 문제점
프론트 HTML tag'name을 그대로 백엔드 로직에 사용함
마크업과 프론트 사정에 따른 hChk, pChk 와 같은 변수명 백엔드에서 실제 용도를 구분하기 어려움
변수명과 주석이 일치하지 않거나 주석의 뜻을 담아내기에 부족한 변수명이 많음
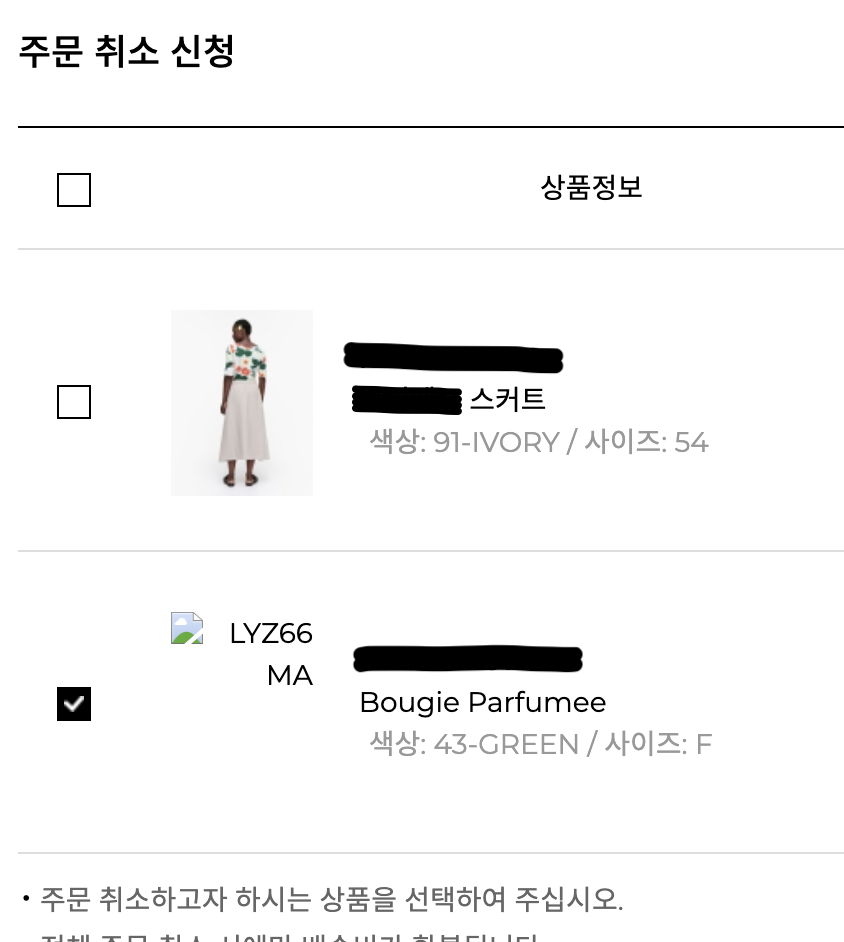
실제 주문취소에서 볼 수 있는 케이스는 아래와 같다.
// bad case
String[] hChk = request.getParameterValues("hChk");//선택여부
// good case
String[] cancelSelectYn = request.getParameterValues("hChk"); // 취소선택여부
위 변수가 가리키고 있는 건 주문 취소 시 상품 별 체크박스 값이다.(아래 스크린샷) 따라서 hChk 라는 이름을 그대로 백엔드 로직에도 차용한다면 코드 전체를 트래킹 해야 하는 수고가 더해진다. 그래서 이름을 취소선택여부, 취소신청여부 등으로 하고 변수명도 이에 맞춰 수정하는 것이 좋다.
주문 취소 상품 선택화면
하지만 실제로 레거시 시스템은 볼륨도 크고 복잡한 상호관계를 이미 가지고 있는 상태기 때문에 변수명만 바꾸기에 위험하다. 래거시 프로젝트 소스코드도 마찬가지이며 따라서 변수명을 바꾸려 할 땐 아래 항목을 점검해서 진행한다.
JSP와 JAVA에서 동일하게 사용하고 있는 변수가 response나 query에서 반드시 동일하도록 짜여 있는지
주석과 변수명이 다르다면 둘 중 어느 것이 맞는지, 둘 다 틀린지
변수명을 바꿨을 때 영향 범위가 백엔드 비즈니스 로직에만 해당되는지
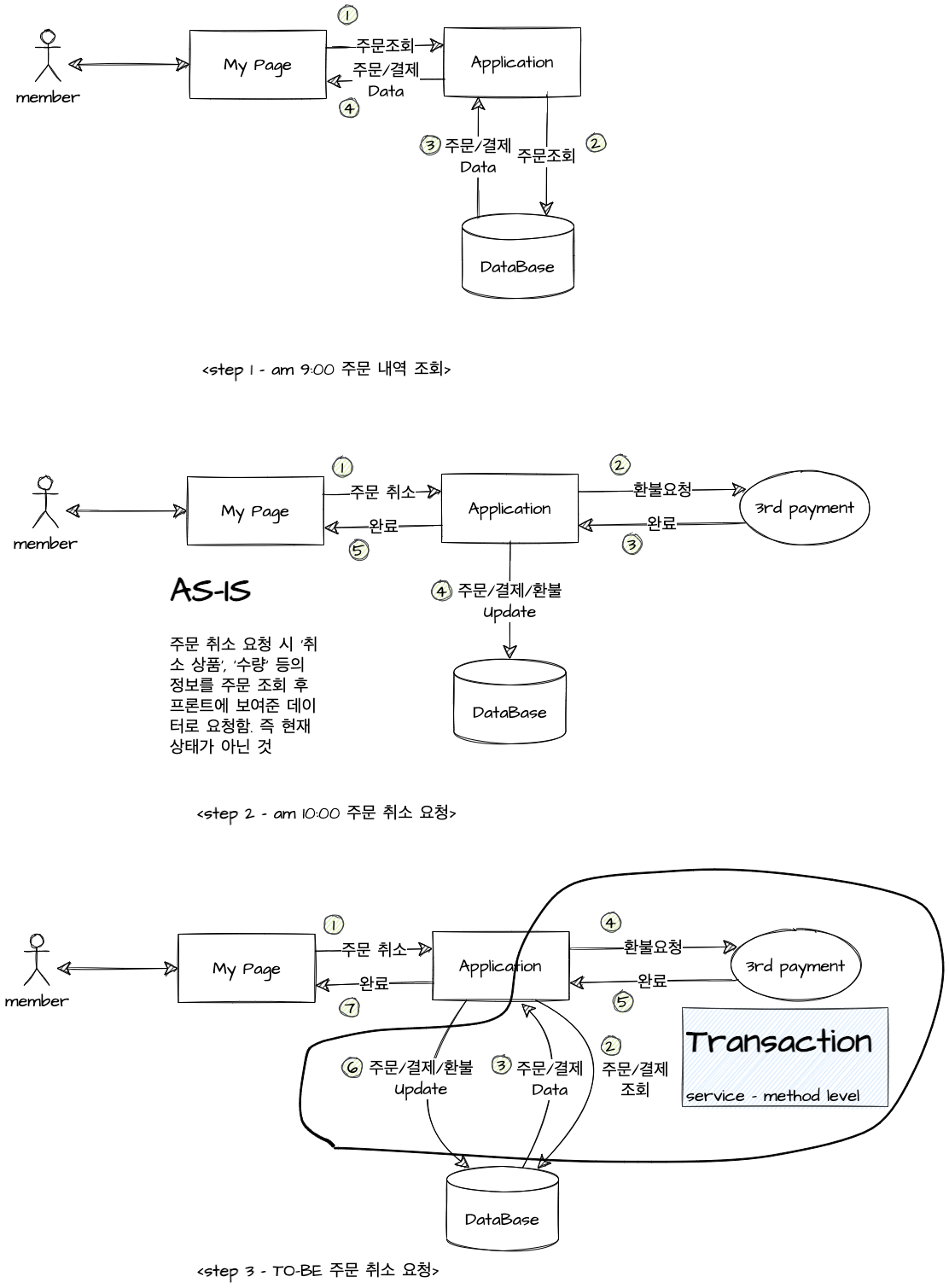
6. 조회와 요청, 트랜젝션
사용자의 화면에 보이는 내용은 화면을 그리는 시점에 유효한 정보이다(화면을 실시간으로 갱신하지 않는한)
현재 프로세스는 <step 2> 와 같고 주문 취소 요청 시 JSP에 뿌려진 주문/결제 값으로 환불요청을 시작한다
때문에 주문 조회 시점과 환불 요청 시점 차이가 있을 때 주문 상태 차이가 발생할 수 있고 중복 발생 가능성 또한 있는 구조다.
개선 프로세스는 <step 3> 와 같이 사용자 요청을 받고 현재 주문과 환불 진행상태 등을 DB에서 조회하는 ② 부터 완료된 주문/결제/환불 정보를 DB에 업데이트하는 ⑥ 까지를 하나의 트랜잭션으로 묶는다.
대부분의 레거시 프로젝트 코드에는 화면에서 가져온 값들로 무언가 처리하는 로직이 많은데 전반적인 수정이 필요하다.
7. 3-tier Architecture
아래 쿼리를 먼저 보자.
// 이런 패턴
, X.BANK_CD <!--은행코드-->
, CASE WHEN X.BANK_CD IS NOT NULL
THEN DECODE(X.BANK_CD, '02', '산업', '03', '기업', '05', '외환', '06', '국민', '07', '수협', '11', '농협', '20', '우리', '23', 'SC제일', '27', '한국씨티', '31', '대구'
, '32', '부산', '34', '광주', '35', '제주', '37', '전북', '39', '경남', '45', '새마을금고', '48', '신협', '71', '우체국', '81', '하나', '88'
, '신한(계좌이체)', '26', '신한(가상계좌)','S0', '동양증권', 'S1', '미래에셋', 'S2', '신한금융투자', 'S3', '삼성증권', 'S6', '한국투자증권' , 'SG', '한화증권')
ELSE '-'
END BANK_NM <!--은행명-->
// 비슷한 패턴
, X.MEMO <!--메모(가상)-->
, NVL(X.MEMO, 'X') SHW_MEMO <!--화면용메모(가상)-->
// 비슷한 패턴
, X.RECP_PSN_TELNO <!--수령인전화번호-->
, CASE WHEN LENGTH(REPLACE(NVL(X.RECP_PSN_TELNO, 'X'), '-', '')) <![CDATA[ < ]]> 9
THEN 'X'
ELSE X.RECP_PSN_TELNO
END SHW_RECP_PSN_TELNO <!--수령인전화번호-->
안좋은 케이스로 보이는 건..
쿼리 안에서 데이터 가공을 한다는 것이다. 게다가 화면에 보여줄 목적인 것들이 꽤 있다.
코드 관리나 관련 메소드가 애플리케이션에 있는게 아니라 쿼리에 들어가 있다.
대부분의 레거시 프로젝트들은 JSP, Spring, Oracle 기반이지만 잘 구분된 계층 구조를 이루고 있지 않다. 해당 계층에서 해야 할 일들이 다른 계층으로 번져간다면 결국 문제가 생길때마다 화면~데이터 모든 영역의 코드를 살펴봐야만 어느 부분이 문제인지 찾아낼 수 있다. 그래서 앞으로 신규 개발하는 화면, 기능은 이러한 강한 결합을 피하고 우리 시스템과 기술이 지향하는 3티어 계층에 맞춰 프로그래밍을 하도록 한다. 추후 가이던스를 마련하고 공유하겠지만 먼저 간단하게 요약하면 아래와 같다.
재사용되거나, 분기 절 내의 복잡한 내용을 메소드로 표현하게 되면 더 나은 가독성을 얻을 수 있다.
기존
if( user.id == post.registerId ) {
// 사용자가 게시물의 작성자 이다.
} else {
// 사용자가 게시물의 작성자가 아니다.
}
개선
boolean isEditable = isOwner( user, post );
if( isEditable ) {
// 사용자가 게시물의 작성자 이다.
} else {
// 사용자가 게시물의 작성자가 아니다.
}
boolean isOwner( User user, Post post ) { return user.id == post.registerId; }
드모르간 법칙
괄호 중첩이 적을수록 가독성이 좋다.
기존
if( !(hasfile && !isPrivate) ) return false;
개선
if( !hasFile || isPrivate ) return false;
복잡한 논리 가독성 향상
한 라인으로 논리를 표현하지 않고, 가독성을 위해 적절한 여러 라인으로 분리하여 보호절과 유사하게 한다.
기존
public class Range {
private int bgn;
private int end;
// this의 bgn이나 end가 other의 bgn이나 end에 속하는지 확인
private boolean isOverlapsWith( Range other ) {
return ( this.bgn >= other.bgn && this.bgn < other.end )
|| ( this.end > other.bgn && this.end <= other.end )
|| ( this.bgn <= other.bgn && this.end >= other.end );
}
}
개선
public class Range {
private int bgn;
private int end;
// this의 bgn이나 end가 other의 bgn이나 end에 속하는지 확인
private boolean isOverlapsWith( Range other ) {
// this가 시작하기 전에 끝난다.
if( other.end <= this.bgn ) return false;
// this가 끝난 후에 시작한다.
if( other.bgn >= this.end ) return false;
// 겹친다.
return true;
}
}
switch 문의 사용
if-else 문은 각 조건문을 iterate 하며 로직을 결정한다. N개의 if-else 구문이 있다면 N번의 조건 여부를 판단한다. switch 문은 입력받은 케이스로 로직이 바로 넘어가게 된다. 일반적으로 4개 이상의 조건일 때 if-else 보다 switch 문을 사용하는 것이 성능에 좋다고 한다.
시간 복잡도
다음은 if-else와 switch의 시간 복잡도이다.
if-else : O(N)
switch : O(logN)
int num = 5;
int ret;
if (num == 0) ret = num;
else if (num == 1) ret = num;
else if (num == 3) ret = num;
else if (num == 5) ret = num;
else if (num == 7) ret = num;
else ret = num;
System.out.println(ret);
int num = 5;
int ret;
switch (num) {
case 0: ret = num; break;
case 1: ret = num; break;
case 3: ret = num; break;
case 5: ret = num; break;
case 7: ret = num; break;
default: ret = num; break;
}
System.out.println(ret);